https://www.deepmind.com/blog/muzero-mastering-go-chess-shogi-and-atari-without-rules
MuZero: Mastering Go, chess, shogi and Atari without rules
In 2016, we introduced AlphaGo, the first artificial intelligence (AI) program to defeat humans at the ancient game of Go. Two years later, its successor - AlphaZero - learned from scratch to master Go, chess and shogi. Now, in a paper in the journal Natur
www.deepmind.com
위 글을 기반으로 작성했습니다.
2016년, 최초로 인간을 이긴 AI 알파고가 등장했다. 2년 뒤 등장한 알파고의 후속 알파 제로는 바둑, 체스, 장기를 마스터하기 위해 인간의 기보 없이 학습을 진행했다. 이로부터 2년이 지난 2020년, 범용 알고리즘을 위한 중요한 진전을 이룬 Muzero가 등장했다. Muzero는 알려지지 않은 환경에서 승리 전략을 계획하는 능력 덕분에 규칙이 알려지지 않은 경우에도 바둑, 체스, 아타리 게임을 마스터했다.
연구자들은 환경을 설명하는 모델을 학습하고, 그 모델을 사용해 최상의 행동을 계획할 수 있는 방법을 찾아왔다. 하지만 상호작용이 복잡하고 알려지지 않은 아타리 같은 영역에서 효과적으로 계획을 세우는데 어려움을 겪었다.
Muzero는 Planning에서 환경에 가장 중요한 측면에 집중한 모델을 학습함으로써 이 문제를 해결했다. AlphaZero의 강력한 트리 탐색 기법과 결합함으로써, Muzero는 체스, 바둑 같은 고전적 planning 과제에서 알파제로의 성능에 필적하는 결과를 보였고, 아타리 벤치마크의 새로운 기록을 세웠다. 이를 통해 강화학습 알고리즘 성능의 비약적 향상을 보여주었다.
새로운 모델로의 일반화
계획을 세우는 능력은 우리가 문제를 해결하고 미래에 대한 결정을 내릴 수 있도록 하는 인간 지능의 중요한 부분이다. 예를 들어, 하늘에 어두운 구름이 생기는 것을 본다면, 우리는 비가 내릴 것이라고 예상하고 우산을 챙겨나갈 것이다. 사람은 이렇게 계획을 세우는 능력을 빠르게 학습하고 새로운 상황에 적용할 수 있다.
연구자들은 모델 기반 Planning, 탐색 기법이라는 두가지 방법을 사용해서 이런 능력을 AI에게 학습시키고자 했다.
알파제로와 같이 탐색 기법을 사용하는 시스템은 체스, 포커와 같은 고전적인 게임에서 괄목할 만한 성공을 거두었지만, 게임의 규칙이나 정확한 시뮬레이터와 같은 환경의 역학 관계에 대한 지식이 전제되어야 한다는 단점이 있다. 따라서 일반적으로 복잡하고 단순한 규칙으로 추출하기 어려운 복잡한 실제 문제에 적용하기가 어렵다.
모델 기반 시스템은 환경의 역학에 대한 정확한 모델을 학습한 다음 이를 계획에 사용하여 이 문제를 해결하는 것을 목표로 한다. 하지만 환경의 모든 측면을 모델링해야 하는 복잡성 때문에 이러한 알고리즘은 아타리처럼 입력되는 정보가 많은 영역에서는 좋은 성능을 내기 어렵다. 지금까지 아타리에서 가장 좋은 결과를 얻은 것은 학습된 모델을 사용하지 않고 다음에 취할 최선의 조치를 추정하는 Model-free 시스템이다.
MuZero는 이전 접근 방식의 한계를 극복하기 위해 다른 접근 방식을 사용한다. MuZero는 전체 환경을 모델링하는 대신 Agent의 의사 결정 과정에 중요한 측면만 모델링한다. 공기 중에 빗방울이 떨어지는 패턴을 모델링하는 것보다 우산이 비를 막아준다는 사실을 아는 것이 더 유용하다는 것을 예로 들 수 있다.
MuZero는 특히 Planning에 중요한 환경의 세 가지 요소를 모델링한다.
1. 가치: 현재 상황이 얼마나 좋은가?
2. 정책: 어떤 조치를 취하는 것이 최선인가?
3. 보상: 마지막 행동이 얼마나 좋은가?
이러한 요소는 모두 심층 신경망을 사용하여 학습되며, MuZero가 특정 행동을 취할 때 어떤 일이 발생하는지 이해하고 그에 따라 계획을 세우는 데 필요하다.


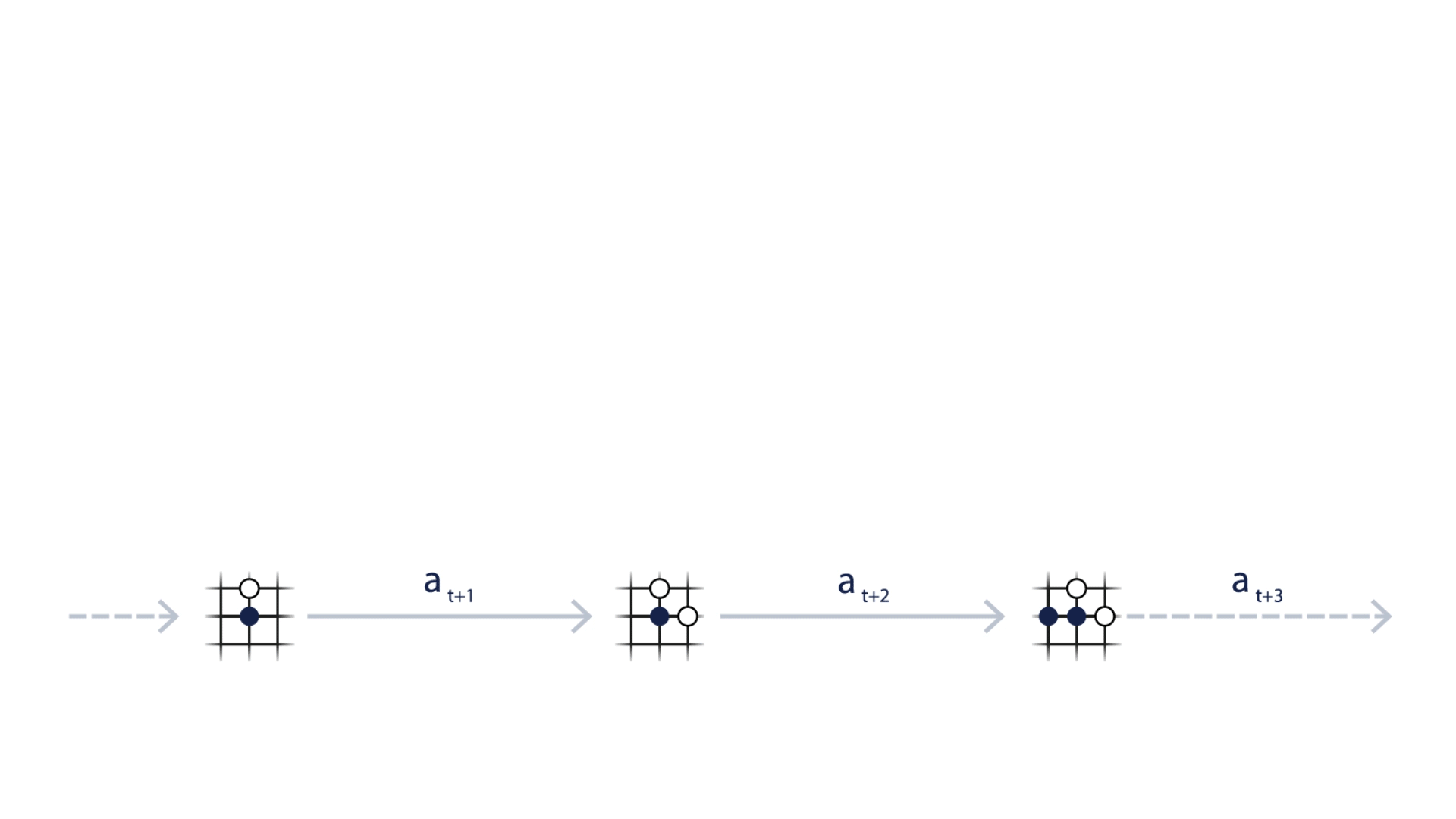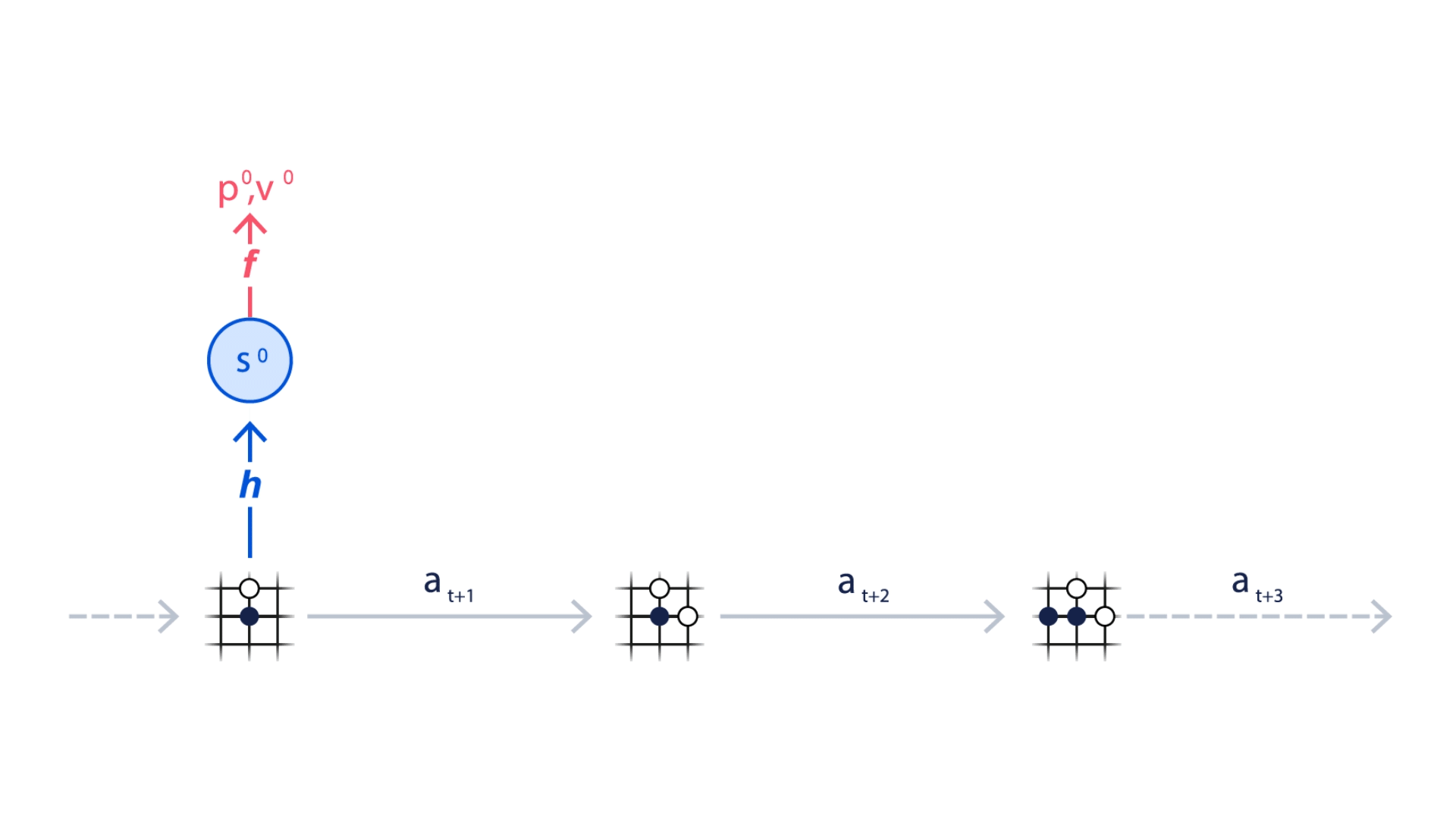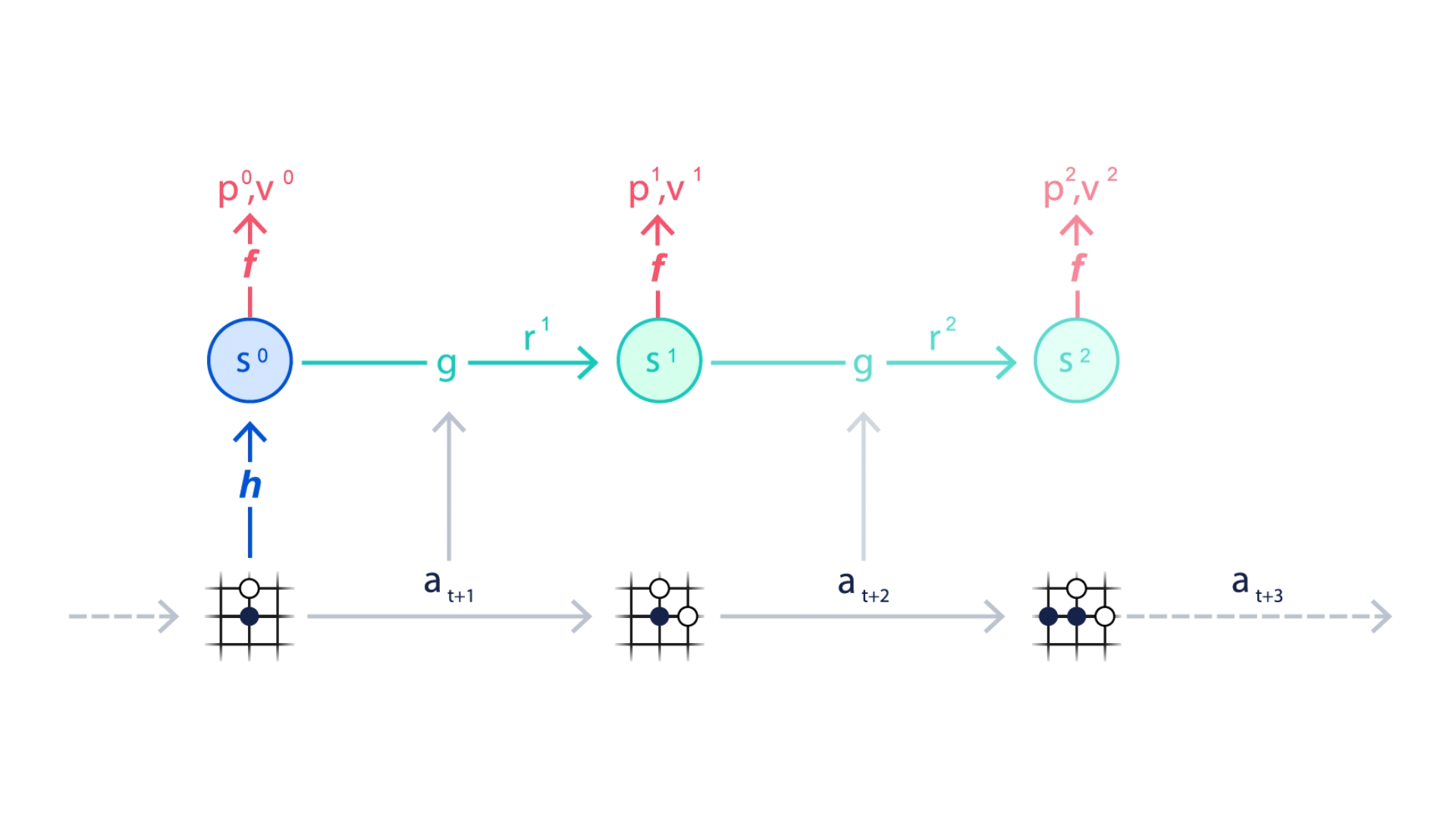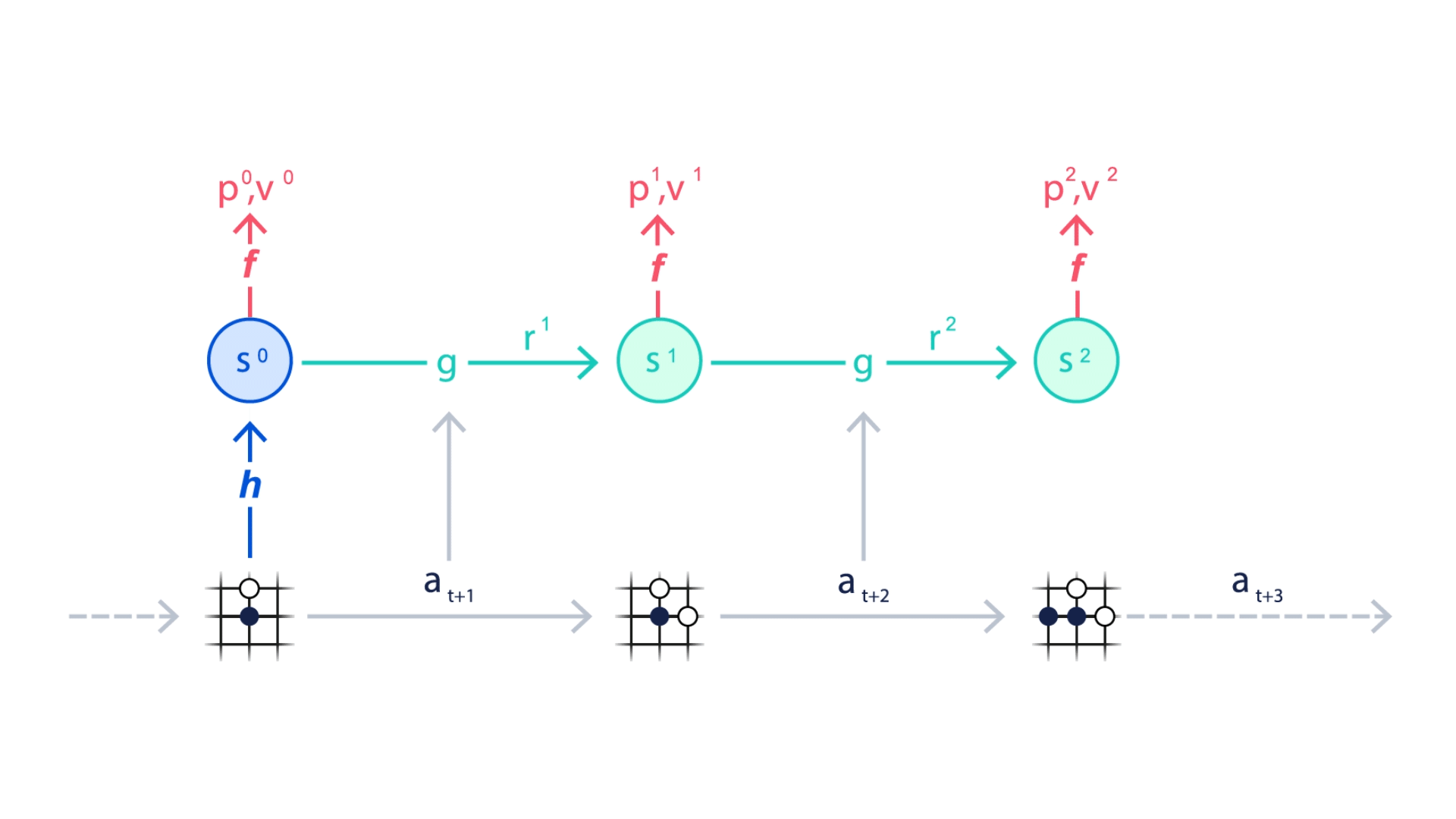
이처럼 신경망을 통해 가치, 정책, 보상 세가지 정보를 학습함으로써, MuZero는 환경이 달라져도 학습된 모델을 다시 사용하여 Planning을 개선할 수 있다.
MuZero 성능
네 가지 도메인에서 MuZero 성능을 평가했다. 어려운 계획 문제에 대한 성능을 평가하기 위해 바둑, 체스, 장기를 사용했으며, 시각적으로 복잡한 문제에 대해서는 Atari를 벤치마크로 사용했다. 모든 경우에서 MuZero는 강화 학습 알고리즘의 새로운 지평을 열었으며, 아타리에서 최고의 성능을 기록하고, 바둑, 체스, 장기에서 규칙을 아는 알파제로의 성능과 맞먹는 결과를 얻었다.

또한 MuZero가 학습된 모델을 활용하여 얼마나 잘 계획을 세울 수 있는지 더 자세히 테스트했다. 한 수 한 수에 승패가 갈리는 바둑의 고전적인 Planning 문제부터 시작했다. 더 많은 계획을 세울수록 더 좋은 결과를 얻을 수 있다는 직관을 확인하기 위해 각 수를 계획할 시간이 더 주어졌을 때 완전히 학습된 버전의 MuZero가 얼마나 더 강해질 수 있는지 측정했다(아래 왼쪽 그래프 참조). 그 결과, 한 수당 시간을 10분의 1초에서 50초로 늘렸을 때 플레이 강도가 1000ElO(플레이어의 상대적 실력을 측정하는 지표) 이상 증가하는 것으로 나타났다. 이는 강한 아마추어 선수와 가장 강한 프로 선수의 차이와 유사하다.

계획이 학습 전반에 걸쳐 이점을 가져다주는지 테스트하기 위해 Atari 게임 Ms 팩맨(위 오른쪽 그래프)에서 별도의 훈련된 MuZero를 사용하여 일련의 실험을 실행했다. 각 인스턴스에는 5개에서 50개까지 다양한 수의 계획 시뮬레이션을 고려할 수 있도록 했다. 그 결과, 각 동작에 대한 계획의 양을 늘리면 MuZero가 더 빠르게 학습하고 더 나은 최종 성능을 달성할 수 있음을 확인했다. 흥미롭게도, 모든 동작을 고려하기에는 너무 적은 수인 6~7개의 시뮬레이션만 고려하도록 허용했을 때에도, 여전히 좋은 성능을 보였다. 이는 MuZero가 동작과 상황을 일반화할 수 있음을 보여준다.
환경 모델을 학습하고 이를 사용해 성공적으로 계획을 세우는 MuZero의 능력은 강화학습에서 범용 알고리즘을 향한 상당한 진전을 보여준다. 이전 버전인 알파제로는 50년 넘게 깨지지 않았던 행렬 곱셈법보다 더 빠른 방법을 찾아내었고, 화학, 양자물리학 등의 복잡한 문제에도 적용되었다. MuZero의 강력한 학습 및 계획 알고리즘에 담긴 아이디어는 게임의 규칙을 알 수 없는 로봇 공학, 산업 시스템 등 복잡한 실제 환경에서 새로운 과제를 해결할 수 있는 길을 열어줄 것이다.