1. 요약
이 논문은 2022 NeuralPS 연합학습 Workshop에서 발표되었다. 논문에서는 연합학습 환경에서 합리적인 행동을 하는 agent(client)를 가정하고, 데이터의 공유를 막는 free-riding 문제를 제시한다. 그리고 계약 이론에서 아이디어를 얻어 free-riding 문제를 막고, 데이터 공유를 최대화하는 accuracy shaping 기반 메커니즘을 제안한다.
2. single agent
문제를 단순화하기 위해 모든 데이터의 가치가 같다고 가정한다. 각 agent는 size가 m인 데이터셋에서 만들어지는 가치함수 v(m) -> [0,1]을 최대화하기를 원한다. 여기서 가치함수 v의 값은 모델의 정확도이다. agent i는 데이터 하나를 생성하는데 $c_{i}$의 비용이 필요하다. m개의 데이터를 생성하는 데는 $c_{i}m$의 비용이 필요하다. 생산한 데이터의 순이익, utility u는 가치에서 비용을 뺀 양으로 결정된다.
$$u_{i}(m) = v(m) - c_{i}m.$$

그림 (a)는 데이터 양 $m$에 따른 모델 정확도 $a(m)$, 비용 $cost_{i}$를 나타낸다. $m^{0}$는 모델을 학습시킬 수 있는 최소 데이터 양이다. 모델이 정확할수록, 정확도를 높이기 어렵다. 같은 양의 데이터가 늘어나도 정확도 상승은 줄어드는 것을 $a(m)$의 기울기가 점점 완만해지는 것에서 확인할 수 있다. $m_{i}^{*}$은 가장 높은 utility를 가지는 최적 데이터 양이다. 그때 가치함수 기울기는 $c_{i}m$인 것을 (a)에서 알 수 있다. cost가 증가해 파란색 그래프의 기울기가 증가한다면, $c_{i}m$를 기울기로 갖는 지점이 앞으로 이동해, $m_{i}^{*}$가 줄어든다는 것을 알 수 있다. 즉 cost가 높을수록 최적 데이터 양 $m_{i}^{*}$이 감소하는 것이다. 그림 (b)는 데이터를 만드는 cost가 적은 경우의 utility 그래프이다. 그림 (a)의 가치에서 비용을 뺀 그래프라고 볼 수 있다. 최적의 utility를 가지는 데이터 양 $m_{i}^{*}$이 0보다 크다. 반면 데이터를 만드는데 드는 cost가 크거나 한 agent가 해결하기 어려운 문제인 경우, utility가 양수인 시점이 존재하지 않을 수 있다. 그림 (c), (d)가 이런 경우다. 이럴 때 agent 입장에서는 아무런 데이터도 만들지 않는 $m_{i}^{*}=0$이 최선의 선택이다.
3. multiple agents
연합학습 환경에서, 메커니즘 $M$은 agent가 기여하는 데이터 양에 따라 다른 가치(정확도)를 가지는 모델을 제공한다. agent $i$가 데이터 $m_{i}$를 기여할 때, 가치가 $v_{i}$인 모델을 받는다면 $M(m_{i}) = v_{i} $이다. agent는 사전에 주어진 메커니즘 $M$를 고려해 얼마나 많은 데이터를 기여할지 결정한다. 메커니즘은 다음과 같은 두 가지 조건을 만족시켜야 한다.
1) 실현 가능성
메커니즘이 제공하는 모델은 모든 agent가 기여한 데이터로 학습한 모델보다 나은 정확도를 가질 수 없다.
2) 개인의 합리성
agent가 데이터를 연합학습 서버에 보냄으로써 얻는 모델은 자신의 데이터만을 이용해 학습시킨 모델보다 나은 성능을 가져야 한다.
합리적인 agent가 많은 데이터를 기여하는 메커니즘을 효과적이라고 할 수 있다. 평형 상태란 agent가 최선의 utility를 얻을 수 있는 가장 합리적인 선택을 한 상태다. 평형상태는 항상 존재하기 때문에, 평형 상태의 데이터 기여량을 비교함으로써 메커니즘의 효과를 비교할 수 있다.

위 메커니즘은 agent가 제공한 데이터와 관계없이 모든 데이터로 학습된 모델을 전달하는 standard FL mechanism이다. 이 메커니즘은 실현 가능성, 개인의 합리성 두 조건을 만족하며 평형 상태 또한 존재한다. 여기서는 기존 메커니즘이 free-riding에 대해 취약하다는 것을 보여준다.
free-riding
가장 적은 cost $c_{min}$를 가지는 agent는 평형 상태에서 $m_{min}^{*}$ 의 데이터를 기여한다. $c_{min}$ 이상의 cost를 가지는 agent i 는 Fig1 (a)에서 알 수 있는 것처럼 $m_{i}^{*} \leq m_{min}^{*}$가 성립한다. 따라서 $m_{min}^{*}$의 데이터가 이미 기여되었기 때문에 agent i가 추가적으로 데이터를 기여하는 경우 value보다 cost가 더 커진다. 따라서 평형 상태에서 각 agent는 다음과 같은 양의 데이터를 기여한다.

이렇게 가장 cost가 낮은 agent만 데이터를 제공하는 것은 연합학습의 효과를 크게 떨어트리는 치명적인 무임승차 문제를 일으킨다.
4. cost를 알 때 메커니즘
여기서는 agent $i$의 데이터 생성 비용 $c_{i}$를 알 때, 평형상태에서 agent의 데이터 기여를 최대화하는 메커니즘을 설계한다.
데이터 극대화 메커니즘
기여한 데이터가 utility가 감소하기 시작하는 지점인 $m_{i}^{*}$ 미만이라면 agent i의 데이터 $m_{i}$만으로 훈련된 모델을 제공한다. agent에게 더 많은 기여를 유도하기 위해 $m_{i}^{*}$ 이상으로 기여한 데이터 $\triangle m$에 대해서는 $(c_{i} + \epsilon)\triangle m$만큼의 보상을 제공한다. 여기서 $\epsilon$은 0 이상의 작은 수로, cost 보다 보상을 높여주는 역할을 한다. $m_{i}^{*}, \triangle m$에 대한 보상의 합이 모든 데이터로 만든 모델의 가치에 도달하는 지점을 $m_{i}^{max}$라고 하자. 아래 그림에서 점 B로 표시된 부분이고, 여기서부터는 agent에게 모든 데이터로 만든 모델을 제공한다. 이를 통해 합리적 agent가 $m_{i}^{*}$개가 아닌, $m_{i}^{max}$개의 데이터를 기여하도록 유도한다.

Fig2에서 회색 그래프는 client i의 데이터로만 학습된 모델의 가치, 초록 그래프는 모든 데이터로 학습된 모델의 가치를 나타낸다. 빨간색 그래프는 메커니즘 M에 의해 client i에게 할당되는 모델의 가치이다. 연합학습에 참여하는 클라이언트가 많다면 모델 전체의 성능을 나타내는 초록색 그래프가 더 높은 위치에 형성되어, 점 B가 점 A에서 멀어진다. 이로 인해 $m_{i}^{max}$는 더 큰 값으로 설정되고, 결국 전체 데이터 기여량이 늘어난다.
검증
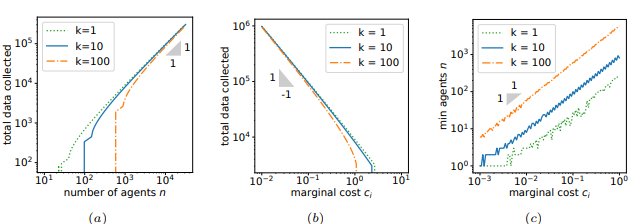
그림 (a)는 학습에 참여하는 agent가 늘어날수록 수집되는 데이터가 증가하는 것을 보여준다. (b)는 데이터 생산 cost가 증가할수록, 수집되는 데이터의 양이 적음을 보여준다. 마지막으로 (c)는 데이터 cost가 크고 문제가 복잡할수록, agent가 데이터를 보내주기 시작하는 threshold ($m_{i}^{max} > 0$)에 도달하기 위해 많은 client가 필요하다는 것을 보여준다.
5. cost를 모를 때 메커니즘
데이터 생성 cost를 알 수 있다는 위 가정과 달리 실제로는 데이터를 생성하는데 드는 비용을 알 수 없는 경우가 많다. 여기서 agent의 데이터 생성 비용이 두 가지가 될 수 있다고 가정한다. 둘 중 낮은 비용이 $\underline{c}$ , 높은 비용이 $\overline{c}$이다. 연합학습 서버는 각 agent가 어떤 cost를 가지는지 알 수 없다. 각 agent는 $p_{i}$의 확률로 cost $\underline{c}$를, $(1 - p_{i})$의 확률로 $\overline{c}$를 가진다. 낮은 cost $\underline{c}$를 가지는 agent는 평형 상태에 $\underline{m}^{*}$만큼 데이터를 기여하고, cost $\overline{c}$인 agent는 $\overline{m}^{*}$만큼 데이터를 기여한다.

Fig 1에서 설명한 것처럼 cost가 증가할수록 평형 상태에서의 데이터 기여가 감소하기 때문에 $\overline{m}^{*} \leq \underline{m}^{*}$이다. 먼저 cost가 높은 agent를 보자. $\overline{m}^{*}$ 이상으로 데이터 기여를 유도하기 위해, $\overline{m}^{*}$ 이상의 데이터 $\triangle m$에 대해서 $(\overline{c} + \epsilon)\triangle m$만큼의 보상을 제공한다. 단, 이 보상은 $m_{i}^{ \uparrow}$까지만 이루어진다. low cost agent의 데이터 기여를 유도하기 위해 $\overline{m}_{i}^{ \uparrow}$ 이상의 기여에 대해서는 보상을 $(\underline{c} + \epsilon)$ 만큼 제공한다. 이렇게 보상을 주었을 때 보상이 모든 데이터로 학습한 모델과 같아지는 시점이 $\underline{m}_{i}^{ \downarrow}$이다. 그 때부터는 모든 데이터로 학습시킨 모델을 agent에 제공한다. 그림에서 $\underline{m}^{max}$ 값은 낮은 cost만을 가정하고 메커니즘을 설계했을 경우, 평형상태의 데이터 기여량이다.
$m_{i}^{ \uparrow}$ 값은 high cost agent가 평형 상태에 기여하는 데이터 양, $\underline{m}_{i}^{ \downarrow}$는 low cost agent가 평형 상태에 기여하는 데이터 양이다. $m_{i}^{ \uparrow}$ 값을 높일수록 high cost agent가 기여하는 데이터 양이 많아진다. 하지만 위 Fig4. 를 보면 점 C가 뒤로 이동할수록 초록색 그래프와 빨간색 그래프가 만나는 지점, 점 D가 작아질 것이라는 것을 알 수 있다. 점 D가 작아진다는 것은 low cost agent가 기여하는 데이터 양이 작아진다는 것이다. 따라서 적절한 $m_{i}^{ \uparrow}$ 값을 선택해, cost가 높은 agent와 낮은 agent의 기여량을 최적화하는 것이 중요하다. agent의 cost가 낮을 확률이 높을수록 $m_{i}^{ \uparrow}$ 값을 작게 선택하여, $\underline{m}_{i}^{ \downarrow}$ 크기를 증가시켜야 한다.
6. review
연합학습의 incentive를 다룬 논문은 처음 읽어보았다. 모든 data의 value와 cost가 고정되어 있다는 가정이 너무 strict하게 느껴졌다. gradient based sample selection처럼 data 가치를 평가해 incentive를 부여하는 것도 좋을 것 같다. 또한 $m_{i}^{*}$ 보다 적은 데이터 기여에 대해서는 agent 자신의 데이터로만 학습시킨 모델을 제공한다면, $m_{i}^{*}$ 만큼 데이터를 기여하기에 자원이 불충분한 agent는 연합학습에 참여할 동기를 잃을 수 있다는 생각도 들었다.



