Distillation이란, model이 학습한 지식을 효과적으로 압축하고, 전달할 수 있는 방법이다. Distillation에 대한 자세한 설명은 아래 글을 참고하자.
https://baeseongsu.github.io/posts/knowledge-distillation/
딥러닝 모델 지식의 증류기법, Knowledge Distillation
A minimal, portfolio, sidebar, bootstrap Jekyll theme with responsive web design and focuses on text presentation.
baeseongsu.github.io
1. Distillation in FL

모든 device에서 공유할 수 있는 public 데이터가 있는 환경에서 distillation은 강력한 힘을 발휘한다. distillation 기반 FL 아키텍처는 크게 네 가지 유형으로 나눌 수 있다: (1) 각 client가 개인화된 모델을 학습하기 위한 distillation, (2) 더 강력한 서버 모델을 학습하기 위한 distillation , (3) FL 클라이언트와 FL 서버 모두에 대한 양방향 distillation , (4) 클라이언트 간의 distillation. 먼저 각 방법의 대표적인 논문에 대해서 간단하게 알아보자.
(1) Distillation to client
FL 환경에서 distillation을 다룬 첫번째 연구 FedMD는client가 다양한 구조의 모델을 사용할 수 있게 한다. 학습은 public dataset에서의 class별 평균 Score를 바탕으로 계산된 consensus를 통해서 진행된다. Comminication round마다 각 client는 업데이트 된 consensus를 바탕으로 자신의 모델을 학습시키고, 자신의 데이터로 fine-tuning한다. 이 방법을 통해 client는 다른 클라이언트의 데이터까지 활용해, 자신만의 개인화된 모델을 얻을 수 있다.
또 다른 논문은 client에 지식을 증류하는 data-free distillation 프레임워크 FedGen을 제안한다. 생성모델이 FL 서버에서 학습되어 클라이언트에 보내진다. 학습된 생성모델은 클라이언트에서 데이터를 증강하여, local 학습을 좀 더 좋은 방향으로 유도한다.
(2) Distillation to server
FedDF는 각 client가 디바이스의 다양한 computational capability로 인해 다른 모델 구조를 가진다고 가정한다. 서버는 각기 다른 유형의 모델을 대표하는 p개의 prototype 모델을 만든다. 각 communication round에, 같은 모델 구조를 가지는 client 사이에 연합학습을 진행하여 student 모델을 초기화한다. 그리고 public unlabeled data로 ensemble distillation을 통한 cross-architecture learning을 진행한다. 이 방법에 대해서는 뒤에서 더욱 구체적으로 살펴보자.
(3) Distilation between server and client
Federated Group Knowledge Transfer (FedGKT)는 자원이 제한된 client 모델의 개인화 성능을 높이기 위한 알고리즘이다. 이 방식은 양방향 distillation을 활용해 edge device와 서버의 모델을 학습시키기 위해 alternating minimization을 사용한다. 서버 모델은 client 모델에서 추출된 측징을 input으로 사용하고, client 모델의 soft label, 실제 정답과 자신의 output 사이의 오차를 줄이기 위해 KL-divergence loss를 사용한다. 이를 통해서, 서버 모델은 client 모델로부터 지식을 효과적으로 흡수할 수 있다. 이와 유사하게, 각 client의 모델은 자신의 데이터와 서버가 예측한 soft label로 KL-divergence loss를 계산한다. 이는 서버에서 client로 지식 전달을 촉진한다. 이런 양방향 distilation을 통해, edge client에서 연산 능력이 더 좋은 서버로 연산 부담이 옮겨가게 된다. 반면 이런 방식은 실제 label이 서버로 업로드 되기 때문에, privacy risk를 가진다.
(4) Distilation between clients
D-Distillation은 아키텍쳐와 상관없이 적용할 수 있는 분산학습 알고리즘이다. 이 알고리즘은 모든 edge device가 제한된 개수의 이웃 디바이스와 연결되어 있는 IoT FL 상황을 가정한다. 또한 semi-supervised 알고리즘으로, local training은 private 데이터에서 이루어지고, 연합학습은 unlabeled public 데이터에서 이루어진다. communication round마다, client는 이웃 device와 soft label을 주고받는다. 그리고 consensus 알고리즘에 따라, 자신의 ouput을 변경한다. 업데이트된 output은 자신의 loss를 정규화하여 model의 weight를 업데이트하는데 사용된다. 이런 과정은 네트워크에서 이웃 device 사이의 지식 전달을 촉진한다.
2. FedDF
다양한 모델 구조를 가지는 client에서 server로 distillation을 진행하는 FedDF에 대해서 좀 더 자세하게 알아보자.
1) Approach
FedDF에서 서버는 여러 모델의 output에 대한 distillation을 진행해야 한다. 이를 위해, teacher model은 서버의 unlabeled data로 평가되고, 모델의 logit output은 server의 student model 학습에 사용된다,

위 식은 student model의 output이다. 위 식에서 KL은 KL-divergence loss를, $\sigma$는 softmax function을, $\eta$는 step size를 의미한다. 결과적으로 student model은 여러 teacher model(client)의 평균 logit에 가까워지도록 학습을 진행하게 된다.
2) Experiments

FedAvg와 FedDF를 다양한 label 불균형 환경에서 비교한 결과, label이 불균형 할수록, distillation을 사용한 FedDF가 더 좋은 성능을 보였다. 하지만 communication round마다 진행한 local epoch이 20번 미만인 경우에는 FedAvg보다 좋지 않은 성능을 보였다. 또한 여러 하이퍼파라미터 세팅을 비교한 결과, 학습에 참여하는 client의 비중이 높을수록 학습 효과가 크게 개선되는 모습을 보인다. 결과적으로 각 client의 모델이 높은 다양성(label 불균형, sampling 비율)을 가지고 해당 client에 데이터를 많이 학습할 수록(local epoch 증가), FedDF가 상대적으로 더 좋은 성능을 보인다는 것을 알 수 있다.

위 그래프 (a)에서는 distillation datset이 포함하는 class 수가 적더라도, distillation 성능에 크게 영향을 미치지 않는다는 것을 보여준다. (b)는 distillation dataset이 전체 데이터에 1%만을 차지하더라도, 좋은 성능을 보인다는 것을 보여준다. (c)에서는 좋은 성능을 얻기 위해서는 student 모델을 업데이트하는 횟수를 의미하는 distillation step이 100번 이상은 진행되어야 한다는 것을 알 수 있다.
3. FedKT
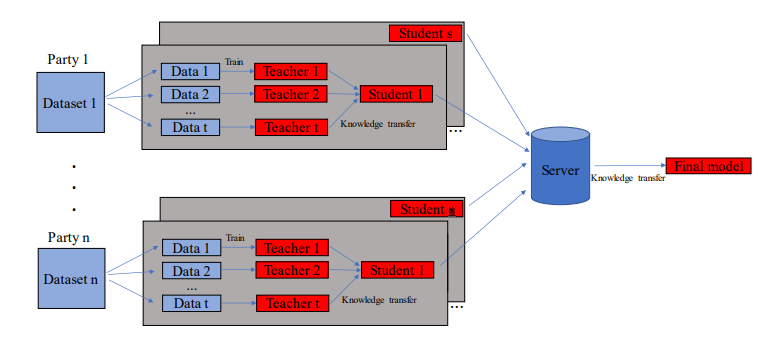
서버와 client 사이에 통신을 한번만 진행하는 One-Shot FL Setting에서는 aggregation 방식으로 distilation이 많이 활용된다. 그 중에서도 distillation을 가장 적극적으로 활용하는 방법론은 Cross-Silo FL 알고리즘인 FedKT이다. FedKT는 각 client의 데이터를 몇개의 subset으로 나누고, subset 마다 다른 teacher model이 데이터를 학습한다. teacher model은 distillation을 통해 client별로 하나의 student 모델을 학습시키고, student model에서 server의 final model로 최종적인 지식 전이가 일어난다.

참고자료
1. Distillation in FL
<Towards Personalized Federated Learning> - IV. STRATEGY II: LEARNING PERSONALIZED MODELS
2. FedDF
<Ensemble Distillation for Robust Model Fusion in Federated Learning>
3. Distillation in One-Shot FL
<One-Shot Federated Learning>
<Practical One-Shot Federated Learning for Cross-Silo Setting>



