https://scikit-learn.org/stable/modules/cross_validation.html
3.1. Cross-validation: evaluating estimator performance
Learning the parameters of a prediction function and testing it on the same data is a methodological mistake: a model that would just repeat the labels of the samples that it has just seen would ha...
scikit-learn.org
scikit-learn 공식 문서의 Cross-validation: evaluating estimator performance를 기반으로 작성된 글입니다.
1. Cross-validation 개념과 등장 배경
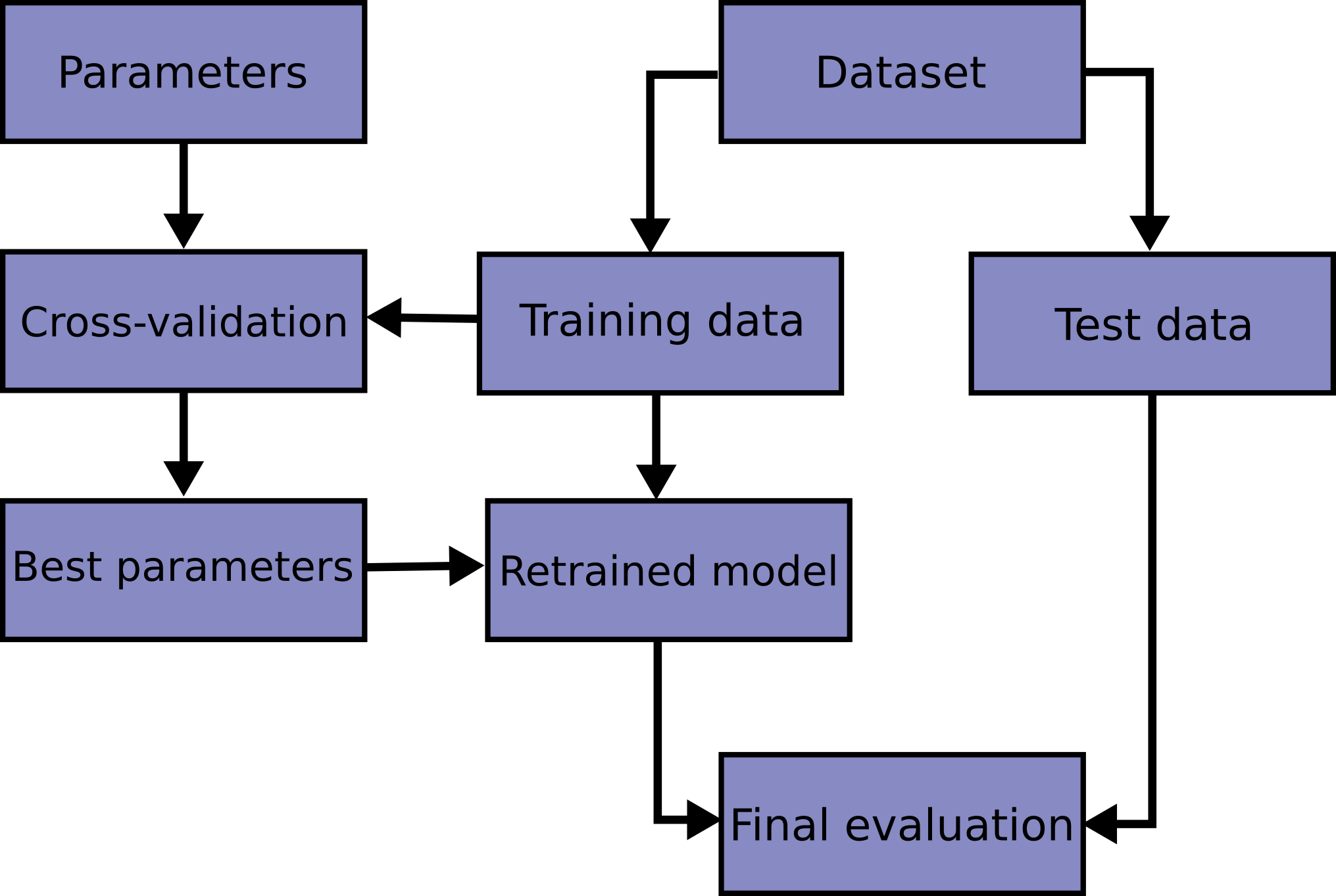
신경망을 비롯한 예측 함수의 train과 test를 같은 데이터에서 진행하는 것은 새로운 데이터에 대한 예측을 할 수 없는 잘못된 방법이다. 이러한 과적합을 막기 위해 머신러닝에서는 일부 데이터를 테스트 셋으로 따로 분리해둔다. 아래 그림은 모델 학습에서 일반적으로 cross validation이 사용되는 흐름이다. 보통 train data를 K-fold 등의 cross-validation 방법으로 나누고, 최적의 파라미터를 선정한다. 마지막으로 test 데이터를 사용해서 이렇게 얻은 모델을 평가한다.
scikit-learn에서는 다음과 같이 train_test_split 함수를 이용해 간단하게 train 데이터와 test 데이터를 나눌 수 있다.
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn import svm
X, y = datasets.load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=0)
clf = svm.SVC(kernel='linear', C=1).fit(X_train, y_train)
clf.score(X_test, y_test)
estimator의 다양한 세팅(hypermarameter)을 평가할 때 estimator가 최적의 성능을 낼 때까지 파라미터가 변할 수 있기 때문에, 여전히 과적합의 위험이 존재한다. test 데이터에 대한 정보가 모델에게로 새어나가, 평가 지표가 더이상 일반화된 성능을 나타낼 수 없는 것이다. 이를 해결하기 위해, validation set이 존재한다. train set에서 학습이 진행되고, validation set에서 검증이 진행되어 학습을 성공적으로 마친다면, test set에서 최종 평가가 이루어지는 것이다.
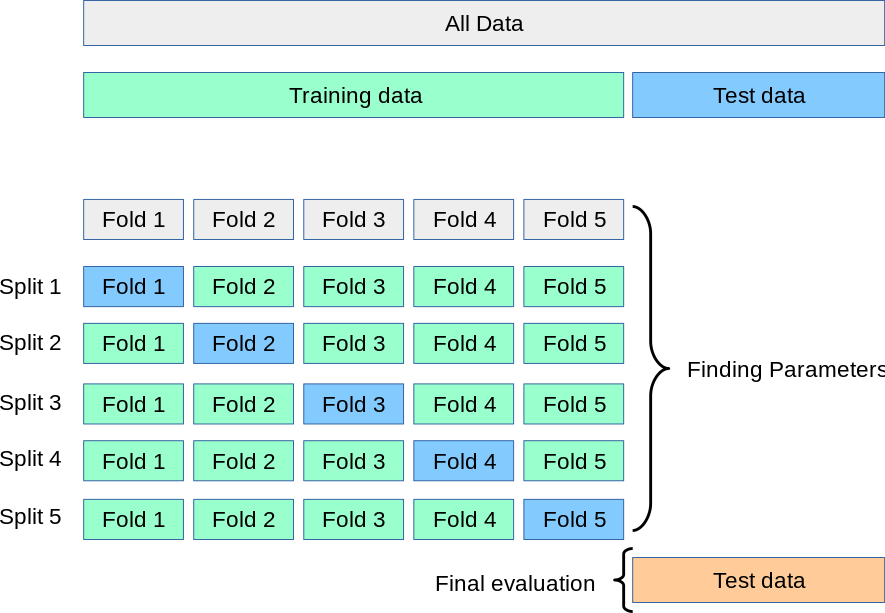
그러나 사용 가능한 데이터를 세가지 세트로 분할한다면 모델 학습에 사용할 수 있는 샘플 숫자는 크게 줄어들 수 있다. 또한 어떤 데이터를 validation, test 세트로 선택할지에 따라서 결과가 달라질 수 있다. 이에 대한 해결책이 cross-validation (CV)이다. 이 방법을 사용하면 더 이상 validation set이 필요하지 않다. 가장 기본적인 CV 방법인 k-fold에서는, 전체 데이터가 k개의 작은 집합으로 분할된다. 그리고 다음과 같은 과정을 k번 반복한다.
- 모델이 k - 1개의 집합을 train data로 사용하여 학습된다.
- 나머지 데이터로 validation을 진행한다.
k-fold 방식에서 성능은 loop에서 계산된 값의 평균으로 측정된다. 이 방식은 계산 비용이 많이 들 수 있지만, 데이터를 효과적으로 사용하기 때문에 샘플 수가 적은 문제에서 이점을 가진다.
2. cross-validated metrics
scikit-learn에서 cross-validation을 사용하는 가장 간단한 방법은 데이터셋과 estimator에서 cross_val_score 함수를 호출하는 것이다. 아래 예시는 5번 k-flod를 반복하여 linear kernel SVM의 정확도를 측정하는 방법을 보여준다.
from sklearn.model_selection import cross_val_score
clf = svm.SVC(kernel='linear', C=1, random_state=42)
scores = cross_val_score(clf, X, y, cv=5)
print("%0.2f accuracy with a standard deviation of %0.2f" % (scores.mean(), scores.std()))
이 외에도 평가 함수를 자유롭게 지정할 수 있으며, 학습 시간과 수렴 시간을 리턴하는 cross_validate 함수를 사용할 수 있다.
from sklearn.model_selection import cross_validate
from sklearn.metrics import recall_score
scoring = ['precision_macro', 'recall_macro']
clf = svm.SVC(kernel='linear', C=1, random_state=0)
scores = cross_validate(clf, X, y, scoring=scoring)
print(sorted(scores.keys()))
>> ['fit_time', 'score_time', 'test_precision_macro', 'test_recall_macro']
print(scores['test_recall_macro'])
>>array([0.96..., 1. ..., 0.96..., 0.96..., 1. ])
3. cross validation iterator
KFold
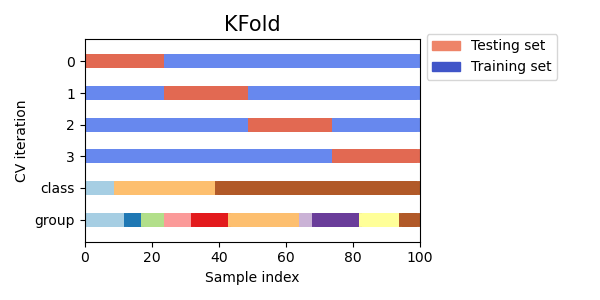
가장 기본 iterator인 KFold는 모든 데이터를 (가능한한) 같은 크기의 K개 데이터 셋으로 나눈다. 나누어진 각 데이터 셋은 fold라고 불린다. k-1개의 fold를 이용해 train을, 나머지 한 fold를 이용해 test를 진행한다. 아래는 4개 sample이 사용된 데이터 셋을 2-fold로 구분 KFold의 사용 예제이다. 각 iteration에서 KFold.split은 train, test set의 index를 리턴한다.
import numpy as np
from sklearn.model_selection import KFold
X = ["a", "b", "c", "d"]
kf = KFold(n_splits=2)
for train, test in kf.split(X):
print("%s %s" % (train, test))
>>[2 3] [0 1]
>>[0 1] [2 3]아래 표는 KFold의 데이터 분할 예시를 보여준다. 데이터가 속한 class나 group(데이터를 얻은 환경)에 상관 없이 데이터를 분할하는 것을 확인할 수 있다.
RepeatedKFold
다음으로, RepeatedKFold는 K-Fold를 n 차례 반복한다. 이 함수는 KFold를 n 차례 반복하며 각 차례에 다른 train-test split을 만들고 싶을 때 사용할 수 있다. 아래 코드는 2-fold를 2차례 반복하는 예시이다. 기존 KFold와 비교하여 n_repeats, random_state를 추가로 인자로 받는다.
import numpy as np
from sklearn.model_selection import RepeatedKFold
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
random_state = 12883823
rkf = RepeatedKFold(n_splits=2, n_repeats=2, random_state=random_state)
for train, test in rkf.split(X):
print("%s %s" % (train, test))
>>[2 3] [0 1]
>>[0 1] [2 3]
>>[0 2] [1 3]
>>[1 3] [0 2]Stratified k-fold
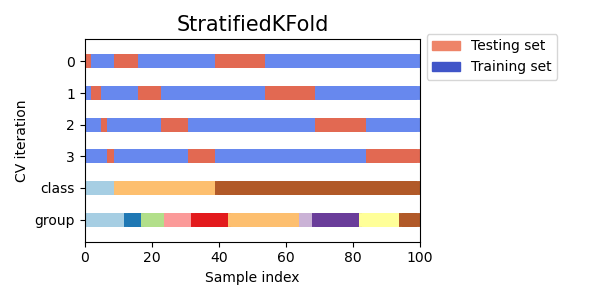
각 fold가 class를 최대한 같은 비율로 포함하도록 하는 k-fold의 변형이다. 아래는 50개의 sample이 있을 때 stratified 3-fold를 사용한 예제 코드이다. 사용법은 기본 KFold처럼 데이터를 몇개의 fold로 나눌지만 정해주면 된다.
from sklearn.model_selection import StratifiedKFold, KFold
import numpy as np
X, y = np.ones((50, 1)), np.hstack(([0] * 45, [1] * 5))
skf = StratifiedKFold(n_splits=3)
for train, test in skf.split(X, y):
print('train - {} | test - {}'.format(
np.bincount(y[train]), np.bincount(y[test])))
>>train - [30 3] | test - [15 2]
>>train - [30 3] | test - [15 2]
>>train - [30 4] | test - [15 1]아래 표는 Stratified k-fold를 사용해서 데이터를 분할한 예시이다. train, test 분할이 class마다 균일하게 이루어진 것을 확인할 수 있다.
'데이터사이언스 > 머신러닝' 카테고리의 다른 글
| pycaret을 활용한 간편한 모델 Optimization (0) | 2023.04.23 |
|---|---|
| Expactation Maximization (0) | 2023.03.12 |
| [scikit-learn] RandomForestClassifier 알아보기 (0) | 2022.11.07 |
| [강화학습] CartPole에서 Actor-Critic 구현하기 (0) | 2022.11.02 |
| BERT와 pytorch를 사용한 binary classification (0) | 2022.10.31 |

