python에서 가장 많이 사용되는 AutoML 라이브러리 중 하나인 pycaret은 간편하게 여러 모델을 비교하고, 성능을 최적화할 수 있다는 장점을 가지고 있다.
1. tune_model
모델의 하이퍼파라미터를 조정하는 가장 기본적 함수로, K-Fold를 사용한다. 각 Fold가 Validation set으로 사용되었을 때, 와 모든 경우에 평균 Metrics를 출력한다. 최적화 매개변수에 정의된 Metric에 따라 가장 적합한 모델이 선택된다. get_metrics 함수를 사용하여 교차 검증 중에 평가된 Metrics에 접근할 수 있다. 사용자 지정 Metrics는 add_metric 및 remove_metric 함수를 사용하여 추가하거나 제거할 수 있다.
from pycaret.regression import *
#n_iter로 반복횟수 설정 가능, 기본 값은 10
best_tune = tune_model(best, n_iter = 50)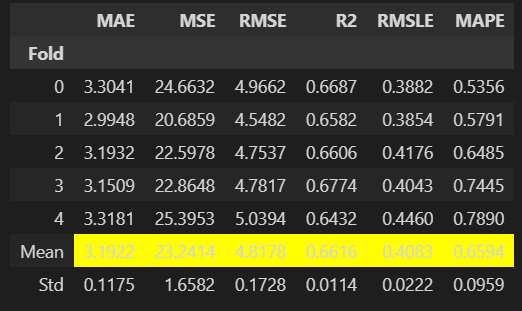
새로운 탐색 공간 정의하기
하이퍼파라미터를 탐색할 범위인 Search Space는 라이브러리의 모든 모델에 대해 PyCaret에 의해 이미 정의되어 있다. 원하는 경우 custom_grid 매개 변수를 사용하여 사용자 정의 그리드를 전달하여 자신만의 검색 공간을 정의할 수 있다.
#RandomForest인 경우 parameter 예시
params = { 'bootstrap': [True],
'max_depth': [10, 20, 30, 50],
'max_features': [2, 3, 4, 5, 6]}
best_tune = tune_model(regressor, n_iter=5, custom_grid = params)
탐색 알고리즘 변경하기
PyCaret에서는 하이퍼파라미터 튜닝을 위해 랜덤, 베이지안, TPE 등의 방법을 사용하는 다양한 라이브러리를 사용할 수 있다. 기본적으로 PyCaret은 sklearn의 랜덤그리드서치를 사용하며, tune_model 함수의 search_library 및search_algorithm 파라미터를 사용하여 이를 변경할 수 있다.
# tune model optuna
tune_model(dt, search_library = 'optuna')
# tune model scikit-optimize
tune_model(dt, search_library = 'scikit-optimize')
# tune model tune-sklearn
tune_model(dt, search_library = 'tune-sklearn', search_algorithm = 'hyperopt')
2. ensemble_model
주어진 여러 estimator를 이용해 추론을 하는 함수다. tune_model과 마찬가지로 각 Fold별, 평균 Metrics를 출력한다. Metrics에는 get_metircs 함수를 이용해 접근할 수 있고, add_metric 및 remove_metric 함수로 사용자 지정 Metric을 추가하거나 제거할 수 있다.
모델 간의 앙상블을 시행할 수 있는 방법은 두가지가 있다. 첫번째는 샘플을 여러번 뽑아서 각 모델을 학습시키고 그 결과를 결합하는 Bagging(Bootstrap Aggregating) 방식이다. 이 방식을 통해 모델의 일반화 성능을 높일 수 있다. 다음으로는 각 모델에서 발생한 오류를 더 잘 해결하는 모델을 학습시키는 방식의 Boosting 방식이다. 이 방식을 활용하면 오답에 더욱 집중할 수 있지만, Outlier에 취약하다는 단점이 있다. pycaret에서 앙상블의 기본 방식은 Bagging이기 때문에 따로 method 인자를 전달하지 않으면, Bagging 방식으로 학습이 진행된다.
bagged_dt = ensemble_model(best, fold = 5, method = 'Boosting')
3. blend_models
함수 인자로 전달된 estimator_list 파라미터로 전달된 모델간에 Soft Voting을 진행하여 결과를 출력한다. Soft Voting은 각 model이 데이터가 어떤 class에 속할지 확률을 합산하여 예측을 진행하는 방식이다. 아래 코드에서는 compare_models에서 n_select 인자를 이용해 5개의 모델을 리턴받고, 그 중 4가지 모델을 사용해 blend_models을 이용한 앙상블을 진행했다.
best = compare_models(sort='mse', n_select = 5)
blender = blend_models(best[:3])4. stack_models
Stacking 방식은 모델의 output의 평균을 내지 않고, 각 모델의 output에 가중치를 부여한 weighted sum을 구한다. 먼저 1단계에서는 각 sub model의 예측 결과를 생성하고, 2단계에서는 각 모델에 해당하는 가중치를 구한다. 다양한 종류의 sub model을 사용한다면 더 나은 결과를 얻을 수 있다. 또 가장 연산량이 많은 방식이기도 하다. 아래는 compare_method로 5개 모델을 리턴받고, 리턴 받은 모델 중 첫번째, 세번째 모델을 stacking하여 앙상블을 진행하는 코드이다.
regresstion taks에서 stack_models는 각 모델의 weight를 구하는 과정에서 기본적으로 LinearRegression를 사용한다. 만약 다른 모델을 사용하고 싶다면 아래처럼 meta_model이라는 파라미터를 지정하여 다른 방식으로 모델의 weight를 구할 수 있다.
best = compare_models(sort='mse', n_select = 5)
blender = blend_models([best[0], best[1]], meta_model = lightgbm)
'데이터사이언스 > 머신러닝' 카테고리의 다른 글
| Cross-validation 개념과 scikit-learn 예제 (1) | 2023.03.26 |
|---|---|
| Expactation Maximization (0) | 2023.03.12 |
| [scikit-learn] RandomForestClassifier 알아보기 (0) | 2022.11.07 |
| [강화학습] CartPole에서 Actor-Critic 구현하기 (0) | 2022.11.02 |
| BERT와 pytorch를 사용한 binary classification (0) | 2022.10.31 |

