1. 소개
이 논문에서는 1) client 데이터 간의 이질성으로 인한 모델 성능 하락, 2) local에서 모델이 업데이트 될 때 이전에 학습했던 정보를 망각하는 catastrophic forgetting 두 가지 문제를 해결하기 위해 FCCL(Federated CrossCorrelation and Continual Learning)을 제안한다. FCCL은 domain shift를 해결하기 위해 다양한 domain의 데이터로 구성된 unlabeled public data로 cross-correlation matrix를 학습한다.. 또한 정보 유출없이 catastrophic forgetting 문제를 해결하기 위해 knowledge distillation을 활용한다. 또한 이미지 분류에 대한 실험을 통해서 FCCL에 대한 효과를 입증한다.
본 논문에서는 데이터 이질성과 모델 이질성을 다음과 같이 정의한다.
- 데이터 이질성: $P_{i}(X|Y) \neq P_{j}(X|Y)$
- 모델 이질성: $Shape(\theta_{i}) Shape(\theta_{j})$
2. Federated Cross-Correlation Learning
이 논문에서 말하는 domain shift는 같은 label을 가지지만, feature가 다른 경우이다. 예를 들어, 손글씨 분류 데이터에서 label은 모두 '9'지만, 연필로 쓴 글자인지 색연필로 쓴 글자인지에 따라 feature가 다른 것을 예로 들 수 있다. domain이 다르면 학습한 데이터가 다르기 때문에 같은 input을 넣더라도 다른 output을 출력할 수 있다. 이를 해결하기 위해 동일한 input에 대해서는 동일한 output 값이 나오도록 장려해야 한다. 또한 private data 보다 상대적으로 다양한 domain에서 수집된 public 데이터를 사용한다.

batch size B, input size D인 unlabeled public data $X_{0}$가 두 모델의 input으로 주어진 경우이다. logit은 C차원 데이터이다. (a) FCCL은 같은 dimension의 logit은 유사하게, 다른 dimenstion의 logit은 다르게 구분하도록 배치 단위로 학습이 진행된다. (b) FedDF는 하나의 input 데이터에 대한 두 모델의 logit이 유사해지도록 학습을 진행한다.
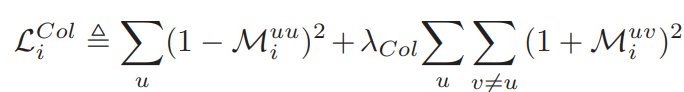
collaborative loss에서 Cross-Correlation Matrix M은 각 logit의 관계를 나타낸다. 대각행렬 $M^{uu}_{i}$의 값은 같은 class의 output에 대한 관계를 나타낸다. distillation 과정에서 같은 데이터를 보고 같은 class라고 예측해야하기 때문에, 대각행렬의 값은 1에 가까워지도록 학습이 진행된다. $M^{uv}_{i}$의 값은 class u와 v의 output의 관계를 나타낸다. 데이터가 어떤 클래스라고 예측을 한다면, 다른 클래스가 아니라는 의미이기 때문에 이 값은 -1에 가깝도록 학습이 진행된다.
3. Federated Continual Learning

여기서는 1) 다른 client의 데이터 2) 자기 자신의 데이터로 학습한 정보를 잊지 않는 것을 목표로 한 Dual-Domain Knowledge Distillation Loss가 사용된다. 1)을 위해서는 외부의 데이터로 학습한 inter-teacher model의 logit이, 2)를 위해서는 내부의 데이터로 학습한 intra-teacher model logit이 활용된다.이를 통해서 내부, 외부 데이터에 대한 distillation을 동시에 진행함으로써 두 domain performance를 모두 향상시킬 수 있다.

위 dual loss에서 사용된 cross entrophy loss를 통해 분류를 위한 의미있는 representation을 학습하고, Dual domain distillation loss는 각 domain에 맞는 정보를 학습할 수 있다. $ \lambda_{Loc} $는 dual loss를 조절하는 coefficient이다.

4. Experiments
실험은 MNIST, SVHN 등 숫자 데이터셋으로 구성된 Digits라는 task와 Art, Clipart 등의 도메인을 가진 이미지로 구성된 Office-Home이라는 task에서 실행되었다. (데이터 이질성) 사용된 모델은 ResNet과 EfiicientNet 등 4가지이다.

실험 결과, 연합학습을 적용하지 않은 SOLO가 가장 낮은 성능을 보였다. public 데이터와 private 데이터의 domain이 다르더라도 연합학습을 적용하는 것이 성능 향상에 좋다는 것을 보여주었다. 또한 FedMD, FedDF 등 다른 distillation 기반 연합학습 알고리즘과 비교했을 때 FCCL이 가장 좋은 성능을 보였다.

위 그림은 FCCL의 correlation Matrix 학습 결과이다. 다른 domain의 class 사이의 연관관계를 잘 학습하여 같은 숫자끼리는 관계가 높은 것으로 학습이 잘 된 모습을 확인할 수 있다.
'데이터사이언스 > federated learning' 카테고리의 다른 글
| Unlabeled dataset을 주고받는 Federated distillation method (0) | 2023.07.30 |
|---|---|
| Labeled distillation data을 교환하는 federated distillation methods (0) | 2023.07.02 |
| Federated Learning의 Aggregation method로서의 Distillation (0) | 2023.06.17 |
| 연합학습 library FederatedScope의 Event-driven Architecture (0) | 2023.05.11 |
| [논문 리뷰] Motely: Benchmarking Heterogeneity and Personalization in Federated Learning (0) | 2023.05.01 |



