1. DS-FL
1) Entropy Reduction Aggregation(ERA)
[1]에서는 aggregation 과정에 Entropy Reduction Aggregation(ERA)라는 방식을 제안하였다. ERA는 softmax 과정에서 temperature를 1보다 낮게 설정하여, distillation에서 사용될 soft target의 entrophy를 낮추는 방식이다.원래 distillation에서 사용되는 soft target은, hard label보다 많은 정보를 가지고 있다고 있다. 예를 들어 MNIST에서 정답이 7인 class가 있다고 하면, 7과 1의 유사성으로 인해서 이 class의 soft label은 1이 0보다는 높은 값을 가지고 있을 것이다. 하지만 높은 non-IID 환경에서 aggregate된 soft target은 이렇게 명확한 정보를 가지고 있지 않을 확률이 높다. 따라서 softmax 과정에서 temperature를 1보다 낮게 설정하여, 더 분명하고 정확한 정보를 전달하는 방식을 제안한다.

2) 실험 결과

위 그래프는 파라미터를 교환하는 기존 FL, label별 평균 soft target을 교환하는 FD를 baseline으로 사용한다. 이 논문에서 제안된 DS-FL은 unlabeled pulic data에 대한 client logit의 평균울 구하는 SA, 여기에 Entrophy reduction을 적용한 ERA까지 총 4가지 방식의 통신 비용 당 정확도를 비교한다.그리고 Public dataset을 2만개로 적용했는데, 지나치게 많은 양이라는 생각이 든다.
먼저 FD는 가장 적은 commnucation cost를 보였지만, 정확도가 매우 낮은 수치를 기록했다. 반면 DS-FL은 communication cost 당 정확도가 가장 높았다. 특히 ERA를 사용하였을 때, 더욱 안정적인 학습이 가능한 모습을 보인다. 또한 특정 정확도에 도달하는데 필요한 통신량을 비교했을 때도, 모든 setting에서 ERA가 가장 적은 양의 통신량을 필요로 했다.
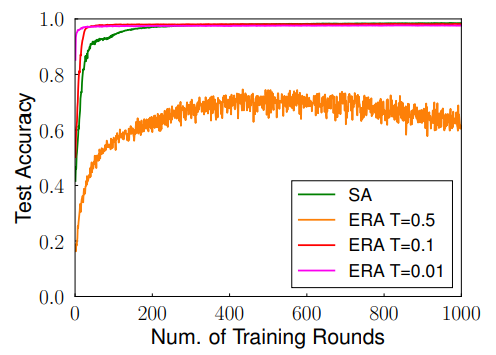
위 그래프는 다른 temperature를 적용했을 때 정확도 변화를 나타내는 그래프이다. T=0.5를 적용하여 entrophy를 크게 했을 때는 학습이 잘 안되는 모습을 확인할 수 있다. 반면 T를 작은 값으로 설정하여 entrophy를 낮추면 학습이 더 잘되는 것을 확인할 수 있다.
2. FEDBE
[2]에 제안하는 FEDBE는 aggregation 과정에서 여러 모델을 하나의 모델로 합치는 것이 아니라, 여러 값들의 분포로 결합한다. 논문에서는 local model이 Gaussian이나 Dirchlet 분포를 따르게 하는 것만으로도 효과적으로 모델을 분배할 수 있다는 것을 보여준다. 실험에서는 데이터가 불균형하고 network가 깊어질수록 FEDBE의 성능이 향상되는 것을 보여준다.
[1]: Distillation-Based Semi-Supervised Federated Learning for Communication-Efficient Collaborative Training with Non-IID Private Data
[2]: FEDBE: MAKING BAYESIAN MODEL ENSEMBLE APPLICABLE TO FEDERATED LEARNING



